(Part 1) The Rise of Context Engineering and Why SoTA Agents Need Specialized Search

Let me share something that might surprise you: LLMs are already good enough for 95% of what businesses need them to do. When they fail—and here's where it gets interesting—it's almost never the model's fault. It's ours.
Think about it this way. An LLM can only work with what you give it. Feed it the right information at the right moment, and it performs like a seasoned portfolio manager who's been analyzing markets for decades. Give it incomplete or noisy data? That same model suddenly can't distinguish between a revenue miss and a rounding error.
This is where context engineering comes in—the art and science of delivering exactly the right information to your model at exactly the right time. At Chaos Labs, we've built AI agents that help traders execute complex strategies, risk systems that protect billions in assets, and intelligence platforms that parse millions of market signals daily. And here's what separates the financial AI that actually ships from the demos that never leave the lab: state-of-the-art search.
Look, everyone's excited about LLMs right now. The demos are incredible, the benchmarks keep climbing, and the possibilities seem endless. But here's the reality check: you can't build an amazing AI application without first building an amazing application, period. And for any data-rich system—especially in finance—that means getting search right.
It doesn't matter if you're running GPT-4, Claude, or the next breakthrough model. If your agent can't find that crucial risk disclosure buried on page 47 of a 10-K, or pull the exact moment an analyst changed their tone on an earnings call, or surface the correlation pattern between two seemingly unrelated market events, then all that inference power is wasted. The most sophisticated reasoning engine in the world can't compensate for missing data.
What Exactly is Context Engineering?
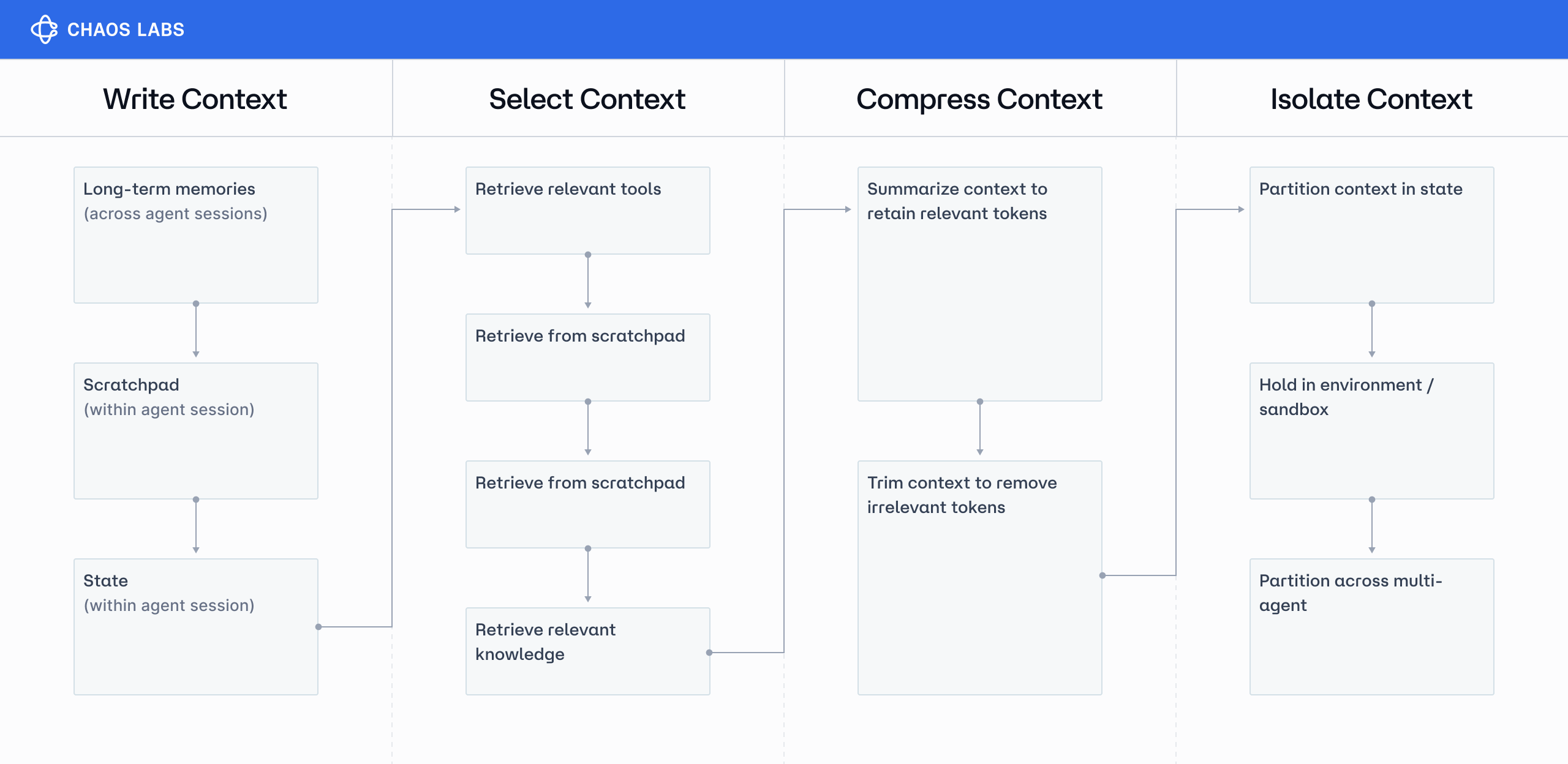
Context engineering is the entire system determining which information reaches your model, when it arrives, and how it's packaged. Think of it as a supply chain for AI intelligence. It has four core stages, shown in the diagram above:
Here's how the pipeline actually works:
- Retrieval (Search): Find every piece of data that could possibly answer the question. This is where the magic happens—or doesn't. Miss the critical datapoint here, and you're done. No amount of clever engineering downstream will save you.
- Filtering: Apply your business rules. Remove anything the user shouldn't see, strip out the noise, and eliminate duplicates. Make fast, ruthless, binary decisions.
- Pruning: Now rank everything that survived and keep only what matters. This is where domain expertise pays off—knowing that a Fed governor's aside comment might matter more than the prepared remarks.
- Compression: Pack it all into the model's context window. Transform raw data into structured insights. Turn 10,000 tokens of market commentary into 500 tokens of actionable intelligence.
Each stage matters, but their impact is asymmetric: flawless compression can’t rescue bad retrieval. That’s why this series focuses on the search layer—designing, training, and evaluating a specialized engine for one of the most information-dense domains on earth: finance.
In upcoming posts we’ll cover:
- How we align hybrid vector–symbolic search to financial semantics.
- Real-time indexing pipelines that stay current at block-level granularity.
- Evaluation harnesses that measure recall, precision, latency, and explainability in dollars-at-risk terms.
Filtering, pruning, and compression deserve deep dives—we’ll tackle those in later installments. First, we’re going straight to the foundation: building a state-of-the-art financial search engine that turns context from a liability into a moat.
Why Search Beats Everything Else in Your RAG Pipeline
Let me be brutally honest about RAG systems. You can optimize every other part of your pipeline to perfection.
Your memory management might be a work of art.
Your compression algorithms could make academics weep with joy.
Your token pruning might be so elegant it belongs in a museum.
None of it matters if search fails.
When a trader asks about forward guidance and your search pulls last quarter's weather discussion instead of the CEO's revised projections, you're done.
When your risk system needs to find exposure correlations and search returns commodity prices instead of counterparty positions, you're done.
This isn't a bug you can patch with better prompting or smarter summarization. Bad retrieval is catastrophic failure, full stop.
At Chaos Labs, we've learned this by building AI systems that handle billions for the largest protocols. Our risk engines protect billions across DeFi protocols and traditional markets. Our trading intelligence parses millions of signals while markets move. And after years of iteration, one truth keeps hitting: search isn't just another component in your stack. It's the foundation that determines whether everything else succeeds or fails.
Think about it: search is the gatekeeper.
It decides what information even gets a chance to be compressed, pruned, or packaged.
Get it right, and your AI suddenly has superpowers—finding alpha in places humans never thought to look. Get it wrong, and it doesn't matter how sophisticated your model is. The quality of your responses will be terrible, and user trust will be lost.
Why Domain-Specific Search Beats General Purpose Every Time
Here's something people miss about search engines: Google is a miracle of engineering precisely because it has to work for everyone. The same system needs to help a mother in Minnesota find paediatric advice, a scientist at CERN locate particle physics papers, and a trader at Citadel research market microstructure. That's an insane challenge, and Google solves it brilliantly—by making intelligent tradeoffs that work reasonably well for billions of different use cases.
But "reasonably well" doesn't cut it in finance.
When you're building search for a specific domain, you can stop making compromises. You can optimize for exactly what your users need, exactly how they need it. And in finance, that changes everything.
The Reality of Financial Data
Let me paint you a picture of what financial search actually deals with:
- Velocity: Order book data that updates thousands of times per second. By the time a general search engine would index it, the opportunity is already gone.
- Permissions: Proprietary research reports with compliance boundaries so complex they make classified documents look simple. One leaked paragraph could end careers.
- Latency: Alternative data feeds where 30 seconds isn't a delay—it's a lifetime. The alpha evaporated 29 seconds ago.
- Precision: Regulatory filings where searching for "million" versus "billion" is the difference between a smart trade and a compliance nightmare.
But here's the kicker: most financial data simply doesn't exist in Google's index.
Think about it. When was the last time you Googled:
- Real-time DEX liquidity pools across Ethereum and Arbitrum
- Order flow from centralized exchanges like Binance or Coinbase
- Stablecoin flows between lending protocols
- Cross-chain transaction patterns during market stress
You can't—because Google doesn't index blockchain data. It doesn't see what's happening in DeFi protocols. It has no idea what's flowing through centralized exchanges.
Even for traditional equities, the gaps are massive:
- Earnings calls: Try finding every time Apple mentioned "supply chain" across the last 20 quarters, ranked by analyst concern level. Or locate which S&P 500 CEOs used the word "challenging" more than five times in their latest call. Google will give you news articles about earnings calls, not the ability to search within them at scale.
- SEC filings: Search for all companies that changed their auditor in the last 6 months and also revised revenue recognition policies. Or find every 10-K where debt-to-EBITDA covenants are within 0.5x of breach. These aren't keyword searches—they require understanding financial semantics buried in structured data that Google doesn't parse.
- Market microstructure: Show me unusual options flow where put/call skew is inverted 30 minutes before a trading halt. Or identify when dark pool volume exceeded 40% for NYSE stocks while VIX exceeded 30. This information doesn't live on web pages—it's trapped in execution data that Google never sees.
The pattern is clear: Google excels at finding some articles about finance. But when you need to search within financial data—to find patterns, detect anomalies, or surface alpha—you're on your own.
This isn't Google's fault. They're not supposed to be a financial data platform. But it illustrates why "just use a better prompt with web search" isn't the answer when you're trying to build institutional-grade financial AI.
That's the difference between a search engine and a financial search engine.
Defining State-of-the-Art Search
For general web queries, state-of-the-art is simple: use Google, Bing, or Perplexity. These APIs have spent decades perfecting retrieval for billions of queries. Need to know the capital of Mongolia or when the iPhone was released? They'll nail it every time.
That really is SoTA—for general knowledge. Two lines of code and you inherit billions in R&D.
But watch what happens when queries get specific to your domain. Here's a dirty secret: you can beat Google with embarrassingly simple logic:
Congratulations—you now outrank Google for your own brand. But let's get real. This won't help when your portfolio manager asks:
- "Which REITs have debt maturing in 2024 with floating rates above 6%?"
- "Show me all mentions of 'supply chain normalization' in semiconductor earnings calls this quarter"
- "What's the correlation between stablecoin outflows and BTC funding rates?"
These aren't typos Google needs to correct or facts Wikipedia has documented. These are precise financial queries that require understanding:
- What a REIT's debt structure actually means
- How to parse management doublespeak in earnings calls
- The relationship between DeFi flows and derivatives markets
The takeaway: Public search APIs are your baseline, not your ceiling. They're fantastic for "what's the weather?" but useless for "which market makers widened spreads during the last Treasury auction?"
For finance—where the difference between "basis points" and "percentage points" can cost millions—we need search that speaks the language, respects the permissions, and delivers the precision that money demands.
That's what we're building. And that's what this series will show you how to create.
What do you know about the world that Google doesn’t?

If the honest answer is "nothing," just use Google's API. But you're here because you have proprietary data Google will never see: order flows, internal research, blockchain mempools, expensive alt-data feeds.
This is your edge—if you can surface it:
1. Precision Retrieval: Pull the exact FOMC paragraph where tone shifted, not 50 Fed blog posts
2. Schema-Aligned Grounding: Return structured data (P&L series, Greeks) not walls of text
3. Latency Discipline: Sub-200ms or death—spreads won't wait
4. Audit Trails: Forensic citations for every claim
Hero Queries
In search engineering, hero queries are the ones that showcase why your specialized system exists—queries where you don't just beat generic search, you make it look irrelevant. Here are ours:
"Unusual stablecoin flows before DeFi liquidations"
- Google: Crypto blogs
- Chaos Labs: Real-time USDC flows pattern-matched against historical cascades
"Energy companies with guidance cuts but insider buying"
- Google: News articles
- Chaos Labs: Form 4s × earnings transcripts, ranked by purchase size
"Find 'pricing power' mentions where margins declined"
- Google: PR releases
- Chaos Labs: 10,000+ transcripts with margin analysis, credibility scored
This is the difference between search and financial search.
Why Chaos Labs Is Building Its Own Engine
In capital markets, alpha doesn't live on the open web. It hides in order books that update 10,000 times per second, analyst notes that never leave Bloomberg terminals, dark pool prints, seven-figure data feeds, and footnotes buried in EDGAR filings. We've spent years building systems to capture and tag this data—flagging forced liquidations, mapping hidden exposures, detecting regime shifts—because Google doesn't even know it exists.
Generic search fails in three ways that kill returns:
1. Missing the needle: Searches for "NVDA supplier risk" return news articles, not the supply chain map from yesterday's investor deck
2. Wrong timeframe: Pulls Q3 data when you need this morning's pre-market action
3. Zero context: Treats "delta" in an options chain the same as "Delta Airlines"
Generic search fails in three ways that matter to anyone moving real money:
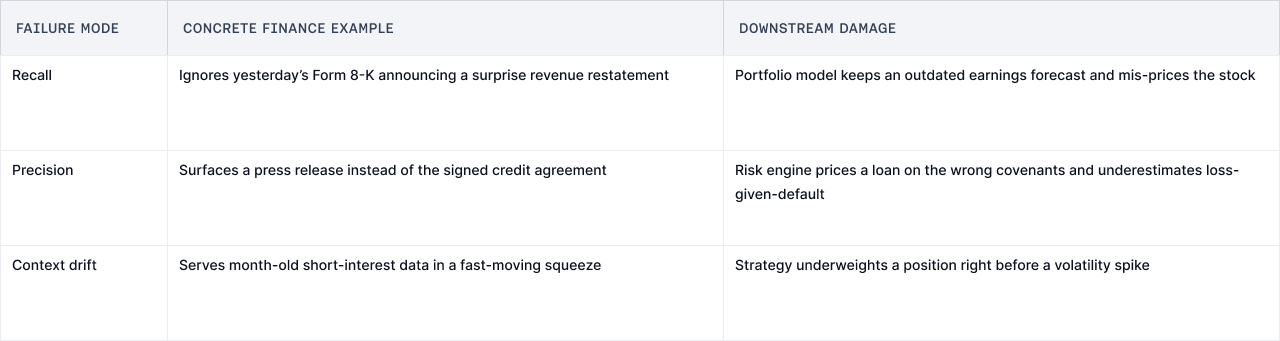
When retrieval fails, everything downstream—your valuations, risk models, execution algos—compounds the error. For a platform managing billions, that's not a bug. It's an existential threat.
What Comes Next
Great AI needs great engineering. Period. So we're going back to first principles and building search that actually understands finance.
Over the next five posts, we'll open our playbook:
- Architect comparisons: keyword vs. vector vs. hybrid approaches
- Real benchmarks: measuring recall and latency on actual trading queries
- Production metrics: what breaks at scale and how we fixed it
- The iterative process: how we went from 70% to 99.7% accuracy
We're sharing this because we believe specialized AI is the future—and it starts with getting search right. Whether you're building for medicine, law, or any domain where precision matters, these principles apply.
Next up: "The Architecture Decision That 10x'd Our Search Performance"
DeFi Rate Swaps: Building Risk Infrastructure for Pendle Boros
We worked with the Pendle team on Boros, a new DeFi primitive that brings funding rate trading onchain with leverage and capital efficiency. Funding rates have never been tradeable in DeFi, requiring us to develop novel risk management systems tailored to an entirely new market structure.
Risk Oracles: Real-Time Risk Management for DeFi
Risk oracles represent the natural evolution of oracle infrastructure, combining our expertise in risk management with protocol-level automation.
Risk Less.
Know More.
Get priority access to the most powerful financial intelligence tool on the market.